编者按:随着深度学习的不断发展,语音识别技术得到了极大的提升,同时为人们的日常生活提供了许多便利 。然而,一个语音模型的训练并非易事,因为语音数据天然存在着获取难、数据标注耗时昂贵的问题,而且还会面临模型漂移、标注数据不足等难题 。因此,迁移学习技术对于语音数据非常重要 。为了解决语音识别的跨领域和跨语言问题,微软亚洲研究院机器学习组和微软(亚洲)互联网工程院提出了跨领域和跨语言语音识别的 CMatch 和 Adapter 方法 。这两项技术是如何提升模型迁移学习性能的?他们又利用了哪些创新技术?让我们从今天的文章中来获得答案吧 。
语音识别就是将人的声音转化为对应的文字,在如今的日常生活中有着重要的应用,例如手机中的语音助手、语音输入;智能家居中的声控照明、智能电视交互;还有影视字幕生成、听录速记等等,以语音识别为核心技术的应用已经屡见不鲜 。但是,语音数据天然存在着获取难、数据标注耗时昂贵的问题 。不同人的方言、口音、说话方式也有所不同 。受限于此,采集到的语音数据绝大多数会面临模型漂移、标注数据不足等问题 。
尤其是语音识别中的跨领域和跨语言场景更是十分具有挑战性 。跨领域指的是在领域 A(如普通麦克风)训练的模型如何迁移到领域 B(如专用麦克风) 。而跨语种则指的是在语言 A(如俄语)上训练的模型如何迁移到语言 B(如捷克语) 。特别是对于一些标注数据稀缺的小语种更是如此 。因此,研究低资源跨语种迁移至关重要 。
为了解决上述难题,微软亚洲研究院提出了用于语音识别的无监督字符级分布适配迁移学习方法 CMatch 和基于适配器架构的参数高效跨语言迁移方法 Adapter 。相关论文已分别被语音领域顶会和顶刊 Interspeech 2021 及 IEEE/ACM TASLP 2022 所接收 。(论文链接,请见文末)
众所周知,基于深度学习的端到端 ASR(自动语音识别)已经可以通过大规模的训练数据和强大的模型得到很好的性能 。但是,训练和测试数据之间可能会因录音设备、环境的不同有着相似却不匹配的分布,导致 ASR 模型测试时的识别精度下降 。而这种领域或分布不匹配的情况非常多样且常见,以至于很难对每个领域的语音数据进行大量收集并标记 。这种情况下模型往往需要借助无监督领域适配来提升其在目标域的表现 。
现有的无监督领域适配方法通常将每个领域视为一个分布,然后进行领域适配,例如领域对抗训练或是特征匹配 。这些方法可能会忽略一些不同领域内细粒度更高的分布知识,例如字符、音素或单词,这在一定程度上会影响适配的效果 。这点在此前的研究《Deep subdomain adaptation network for image classification》[1] 中得到了验证,与在整个域中对齐的传统方法相比,在子域中对齐的图像(即按类标签划分的域)通常可以实现更好的自适应性能 。
微软亚洲研究院提出了一种用于 ASR 的无监督字符级分布匹配方法—— CMatch,以实现在两个不同领域中的每个字符之间执行细粒度的自适应 。在 Libri-Adapt 数据集上进行的实验表明,CMatch 在跨设备和跨环境的适配上相对单词错误率(WER)分别降低了14.39%和16.50% 。同时,研究员们还全面分析了帧级标签分配和基于 Transformer 的领域适配的不同策略 。
以图1为例,通过执行 CMatch 算法,两个领域相同的字符在特征分布中被拉近了:
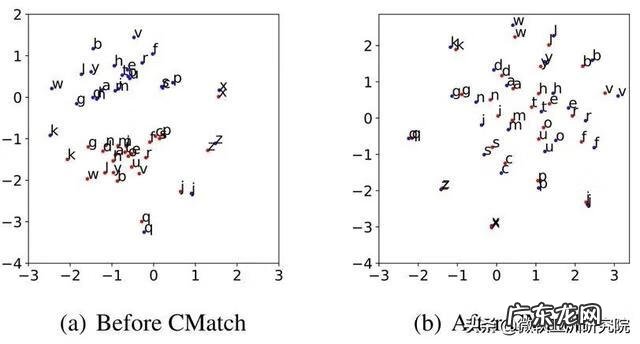
文章插图
- 若不差钱,建议给家里添置这5件小家电,提升生活幸福感!
- 考贵大的mba难度大吗 MBA考试难么
- 南海观世音菩萨在小说中出场的情节有哪些-观音的言行,对唐僧师徒西天取经有哪几方面的影响-请结合相关?
- 小学生清明节手抄报大全?
- 小朋友偏食怎么办?
- 小时候夏夜仰望星空满天都是星星,现在怎么都看不到那种景象了?
- 夜晚很无聊怎么办?
- 如何做好一名优秀的小班幼儿教师研修成果论文?
- 血小板低怎么调理 血小板低是怎么回事
- 今年高考数学那么难,区分度会好吗?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。