这里采用了两种平均方式来反应模型的不同能力:1. 直接平均:没有考虑不同语言内的数据量,对于尤其擅长极少数据的算法会更有优势;2. 加权平均:考虑了不同语言本身的数据量,更适合用来衡量模型在各种情况下的综合表现 。
由结果可以看出:
- 使用迁移学习的方法均明显好于不使用迁移学习的方法,印证了迁移学习的重要性 。
- 全模型微调有着非常强大的效果,对其施加传统的 L2 正则,或是仅微调模型最后几层参数效果都不理想 。
- 原始的 Adapter 在合适的训练方法下基本可以达到和全模型微调相同的水平,说明了 Adapter 在 ASR 任务上的有效性 。
- 本文提出的 SimAdapter 和 MetaAdapter 均进一步提高了 Adapter 的表现,将它们结合后的 SimAdapter+ 更是达到了文中最优的结果 。
- 值得注意的是,MetaAdapter 更擅长数据量极少的情况,而在 SimAdapter 则有着更均衡的表现 。
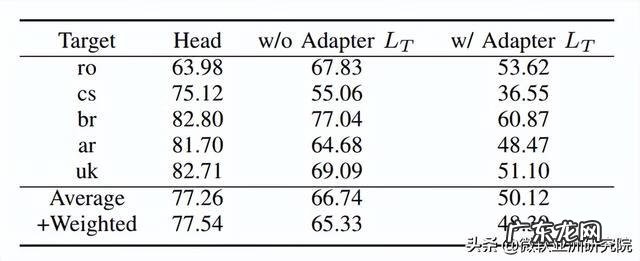
微软亚洲研究院提出了两阶段训练方法以提高 Adapter 在语音识别任务上的表现:模型迁移过程中需要学习一份新语言的词表,如果将该词表和 Adapter 一起训练,由于词嵌入的不断更新,可能会导致 Adapter 学习目标的混乱 。同时学习 Adapter 和词表也可能会词嵌入从而承担一部分 Adapter 的功能,导致 Adapter 无法学习到足够的语言相关特征,造成后续 SimAdapter 的表现下降 。因此,先将主干模型固定住,将新语言的词表映射到模型相同的隐空间(latent space)中,再将词表固定住学习 Adapter,可以达到更好的效果,如表8所示 。

文章插图
表8:二阶段训练法
另外,为了证明 SimAdapter 的确能够从其他语言学习到有用的知识,研究员们设计了两个实验:
其一,尝试去除目标语言本身的 Adapter ,以要求 SimAdapter 仅通过源语言来学习一个对目标语言有用的特征,结果如表9所示:即使没有使用目标语言 Adapter,SimAdapter 依然能够在多数语言上取得较为明显的提升 。
文章插图
表9:SimAdapter 消融实验
其二,在乌克兰语上训练两个不同的 SimAdapter 模型,以分析不同源语言(意大利语和俄语)的贡献 。由于俄语和乌克兰语更相似,使用俄语 Adapter 共同训练的 SimAdapter 应当获得更多收益 。结果显示,使用意大利语 Adapter 的 SimAdapter 的词错误率为48.70,而使用俄语 Adapter 的词错误率仅为47.73,这表明相比意大利语,SimAdapter 的确可以从俄语中学习更多的有用知识来建模乌克兰语 。
微软亚洲研究院已将 CMatch 和 Adapter 代码开源,地址如下:
https://github.com/microsoft/NeuralSpeech/tree/master/CMatchASR
https://github.com/microsoft/NeuralSpeech/tree/master/AdapterASR
相关论文链接:
[1] Deep Subdomain Adaptation Network for Image Classification
https://arxiv.org/abs/2106.09388
[2] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
https://arxiv.org/abs/2006.11477
[3] Parameter-Efficient Transfer Learning for NLP
https://arxiv.org/abs/1902.00751
[4] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
https://arxiv.org/abs/1703.03400
- 若不差钱,建议给家里添置这5件小家电,提升生活幸福感!
- 考贵大的mba难度大吗 MBA考试难么
- 南海观世音菩萨在小说中出场的情节有哪些-观音的言行,对唐僧师徒西天取经有哪几方面的影响-请结合相关?
- 小学生清明节手抄报大全?
- 小朋友偏食怎么办?
- 小时候夏夜仰望星空满天都是星星,现在怎么都看不到那种景象了?
- 夜晚很无聊怎么办?
- 如何做好一名优秀的小班幼儿教师研修成果论文?
- 血小板低怎么调理 血小板低是怎么回事
- 今年高考数学那么难,区分度会好吗?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。