
文章插图
图4:Adapter 结构示意图
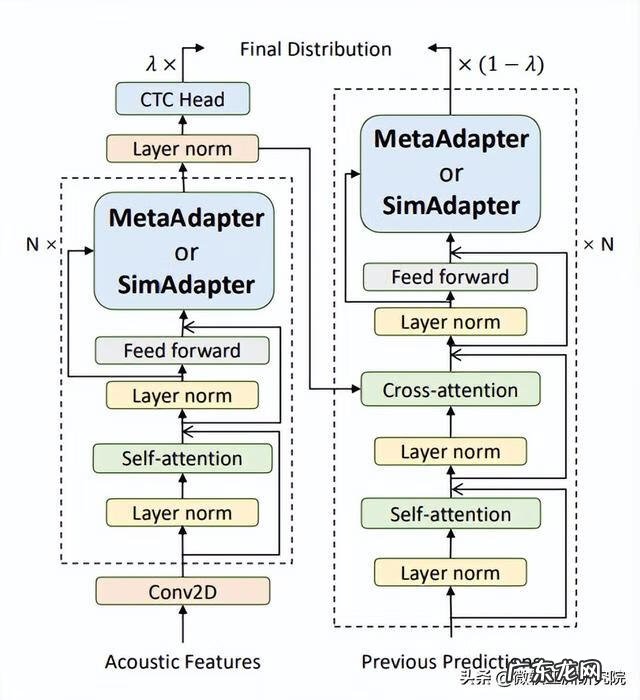
受到 Adapter 的启发,微软亚洲研究院的研究员们尝试使用 Adapter 来解决模型过拟合问题,对如何利用 Adapter 进行高参数效率(parameter-efficient)的预训练多语言 ASR 模型的迁移展开了研究,并提出了 MetaAdapter 和 SimAdapter 来对 Adapter 进一步优化,在仅使用2.5%和15.5%的可训练参数的情况下,使得识别词错误率(WER)相对全模型微调分别降低了2.98%和2.55% 。
微软亚洲研究院使用了自己预训练的多语言模型进行实验,该方法也可以用于 wav2vec2.0 等模型上 。具体来说,模型的主干基于 Transformer 的结构,主要包含12层 Encoder 以及6层 Decoder 模型,结合了11种语料(包含42种语言,总时长约5,000小时)对模型进行预训练 。同时,模型采用了 CTC-Attention 混合损失函数来提升训练的稳定性和加速训练,即在 Encoder 的输出特征上增加 CTC 层,使用 CTC 损失进行约束 。研究员们还将 Adapter 放在前馈层(Feed-Forward Networks)后面,从而对每一层的输出特征进行调节 。
文章插图
图5:主干模型示意图
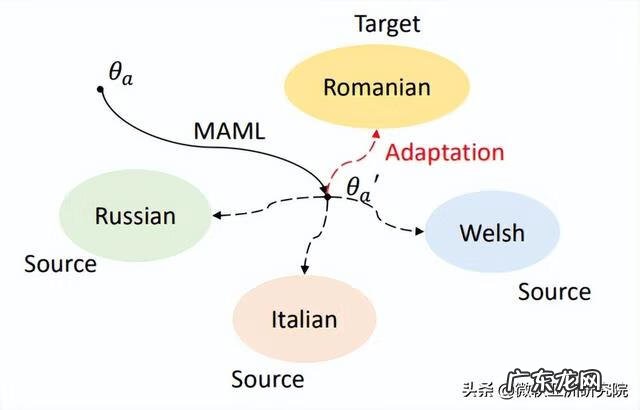
MetaAdapter:MetaAdapter 在结构上与 Adapter 完全一致,唯一不同的是,使用了 MAML (Model-Agnostic Meta-Learning) [4] 元学习算法来学习一个 Adapter 更优的初始化 。MetaAdapter 需要通过学习如何学习多种源语言,从而在各种语言中收集隐含的共享信息,以帮助学习一个新的语言 。实验发现,MetaAdapter 对于过拟合和极少数据量的鲁棒性,以及最终迁移效果均显著强于原始 Adapter。
文章插图
图6:MetaAdapter
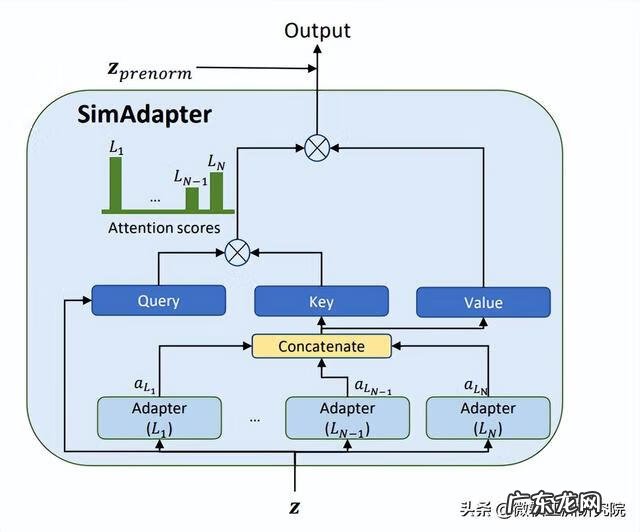
SimAdapter:如果说 MetaAdapter 需要通过收集隐含的共享信息来学习新的语言,那么 SimAdapter 则是显式地要求模型去建模各种语言的相似度关系,从而更好的学习目标语言,其结构如图7所示 。在研究员们看来,多语言模型的原始特征是相对语言无关的,那么如果使用这些特征作为 Query,将各语言 Adapter(包括目标语言)输出的语言强相关特征作为 Key 和 Value,那么就能通过构造注意力机制,从目标语言和源语言中分别提取一些有效信息,作为更好的目标语言特征 。
文章插图
图7:SimAdapter 结构示意图
通过将模型在 Common Voice 的五种低资源语言上进行实验,结果如表7所示 。根据迁移与否以及迁移方式的不同,可以将各种方法分为三类:
- 不迁移(左边栏):包括了传统的 DNN/HMM 混合模型,从头训练的 Transformer(B. 和本文用的主干模型大小结构均一致;S. 指为了抑制过拟合,而将参数量调小的版本),以及将预训练好的模型当作特征提取器,去学习目标语言的输出层 。
- 基于微调的迁移(中间栏):包括了完整模型的微调,以及对于抑制过拟合的尝试(完整模型微调 +L2 正则化、仅微调模型最后几层参数)
- 基于 Adapter 的迁移(右边栏):即本文介绍的各种方法,其中 SimAdapter+ 是结合了 SimAdapter 和 MetaAdapter 的升级版 。

文章插图
表7:MetaAdapter 和 SimAdapter 在 Common Voice 五种低资源语言上的实验结果
- 若不差钱,建议给家里添置这5件小家电,提升生活幸福感!
- 考贵大的mba难度大吗 MBA考试难么
- 南海观世音菩萨在小说中出场的情节有哪些-观音的言行,对唐僧师徒西天取经有哪几方面的影响-请结合相关?
- 小学生清明节手抄报大全?
- 小朋友偏食怎么办?
- 小时候夏夜仰望星空满天都是星星,现在怎么都看不到那种景象了?
- 夜晚很无聊怎么办?
- 如何做好一名优秀的小班幼儿教师研修成果论文?
- 血小板低怎么调理 血小板低是怎么回事
- 今年高考数学那么难,区分度会好吗?
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。