尽管人们对机器学习算法和模型开发的工作有极大的关注 , 但研究者们对于数据收集和数据集的管理往往关注较少 , 但这些研究也非常重要 , 因为机器学习模型所训练的数据可能是下游应用中出现偏见和公平性问题的潜在原因 。 分析机器学习中的数据级联可以帮助我们识别机器学习项目生命周期中 , 可能对结果产生重大影响的环节 。 这项关于数据级联的研究已经在修订后的 PAIR 指南中为数据收集和评估提供了证据支持 , 该指南主要面向的是机器学习的开发人员和设计人员 。
文章图片
图23/25
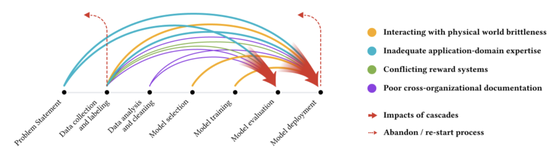
图丨不同颜色的箭头表示各种类型的数据级联 , 每个级联通常起源于上游部分 , 在机器学习开发过程中复合 , 并体现在下游部分 。
更好地理解数据是机器学习研究的一个重要部分 。 我们对一些方法进行研究 , 来更好地理解特定的训练实例对机器学习模型的影响 , 这可以帮助我们发现和调查异常数据 , 因为错误标记的数据或其他类似的问题可能会对整个模型行为产生巨大的影响 。 同时 , 我们还建立了“了解你的数据”(Know Your Data)工具 , 以帮助机器学习研究人员和从业人员更好地了解数据集的属性 。 去年 , 我们还进行了案例研究 , 教你如何使用“了解你的数据”工具来探索数据集中的性别偏见和年龄偏见等问题 。
文章图片
图24/25
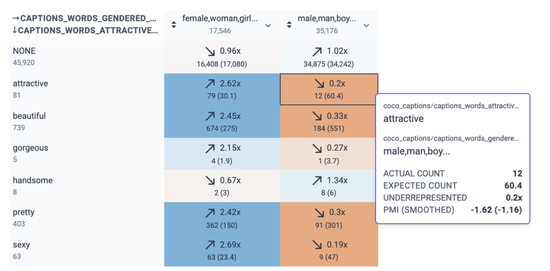
图丨“了解你的数据”截图显示了描述吸引力和性别词汇之间的关系 。 例如 , “有吸引力的”和“男性/男人/男孩”同时出现 12 次 , 但我们预计偶然出现的次数约为 60 次(比例为 0.2 倍) 。 另一方面 , “有吸引力的”和“女性/女人/女孩”同时出现的概率是 2.62 倍 , 超过预计偶然出现的情况 。
因为动态使用基准测试数据集在机器学习作领域中扮演着核心角色 , 了解它也很重要 。 尽管对单个数据集的研究已经变得越来越普遍 , 但对整个领域的动态使用数据集的研究仍然没有得到充分探索 。 在最近的研究工作中 , 我们第一个发表了关于动态的数据集创建、采用和重用的大规模经验性分析 。 这项研究工作为实现更严格的评估 , 以及更公平和社会化的研究提供了见解 。
对每个人来说 , 创建更具包容性和更少偏见的公共数据集是帮助改善机器学习领域的一个重要方法 。 2016 年 , 我们发布了开放图像(Open Images)数据集 , 它包含了约 900 万张图片 , 这些图片用图像标签标注 , 涵盖了数千个对象类别和 600 类的边界框标注 。
去年 , 我们在开放图像扩展(Open Images Extended)集合中引入了包容性人物标注(MIAP)数据集 。 该集合包含更完整人类层次结构的边界框标注 , 每个标注都带有与公平性相关的属性 , 包括感知的性别和年龄范围 。 随着人们越来越致力于减少不公平的偏见 , 作为负责任的人工智能(Responsible AI)研究的一部分 , 我们希望这些标注能够鼓励已经使用开放图像数据集的研究人员在他们的研究中纳入公平性分析 。
我们的团队并不是唯一一个创建数据集来改善机器学习效果的团队 , 我们还创建了“数据集搜索”(Dataset Search)方法 , 使得无论来自哪里的用户都可以在我们的帮助下发现新的和有用的数据集 。
社区互动:
谷歌非常重视应对网络暴力问题 , 包括使用极端语言 , 发表仇恨言论和散播虚假信息等 。 能够可靠、高效和大规模地检测到这些行为 , 对于确保平台安全至关重要 , 同时也能避免机器学习通过无监督学习的方式从网络上大量复制这些负面信息 。 在这方面 , 谷歌开创了领先的 Perspective API 工具 。 但是如何在大规模场景中精准地检测出有害信息仍然是一个复杂的问题 。 在最近 , 我们与不同的学术伙伴合作 , 引入了一个全面的分类法来应对不断变化的网络仇恨和网络骚扰情况 。 谷歌还对如何发现隐蔽性网络暴力 , 如微歧视进行了研究 。 通常 , 微歧视在网络暴力的问题中容易被忽视 。 我们发现 , 对微歧视这种主观概念进行数据注释的传统方法很可能将少数族裔边缘化 。 因此谷歌提出用多任务框架来解决问题的新的分类建模方法 。 此外 , 谷歌的 Jigsaw 团队与乔治华盛顿大学(George Washington University)的研究人员合作 , 通过定性研究和网络层面的内容分析 , 研究了极端的仇恨群体如何在社交媒体平台上散播虚假信息 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。