文 / 学术头条
对于关心人工智能技术进展的读者来说 , 每年年底来自整个谷歌 research 团队撰写的年终总结 , 可谓是必读读物 。
今天 , 由谷歌大神 Jeff Dean 领衔 , 这份总结虽迟但到 。 出于知识传播目的 , “学术头条”现将全文翻译如下 , 以飨读者:
在过去的几十年里 , 我见证了机器学习(ML, Machine Learning)和计算机科学(CS, Computer Science)领域的变化和发展 。
早期的方法往往存在某些缺陷导致了失败 , 然而 , 通过在这些方法上的不断研究和改进 , 最终产生了一系列的现代方法 , 目前这些方法已经非常成功 。 按照这种长期的发展模式 , 在未来几年内 , 我认为我们将会看到一些令人欣喜的进展 , 这些进展最终将造福数十亿人的生活 , 产生比以往任何时候都更大的影响 。
这篇文章中 , 我将重点介绍 ML 中可能产生重大影响的五个领域 。 对于其中的每一项 , 我都会讨论相关的研究(主要是从 2021 年开始) , 以及我们在未来几年可能会看到的方向和进展 。
趋势1:更强大的通用 ML 模型
趋势2:ML 的持续效率提高
趋势3:ML 对个人和社会都越来越有益
趋势4:ML 在科学、健康和可持续发展方面日益增长的效益
趋势5:更深入和广泛地理解 ML
趋势1:更强大的通用 ML 模型
研究人员正在训练比以往更大、更有能力的ML模型 。
例如 , 仅在过去的几年中 , 模型已经在语言领域取得突破性进展 , 从数百亿的数据 tokens 中训练数十亿个参数(如 , 11B 参数 T5 模型) , 发展到数千亿或上万亿的数据 tokens 中训练高达数千亿或上万亿的参数(如 , 密集模型 , 像 OpenAI 的 175 B 参数 GPT3 模型、DeepMind 的 280B 参数 Gopher 模型;稀疏模型 , 如谷歌的 600 B 参数 GShard 模型、1.2T 参数 GLaM 模型) 。 数据集和模型大小的增加导致了各种语言任务的准确性的显著提高 , 这可以从标准自然语言处理(NLP, Natural Language Processing)基准测试任务的全面改进中观察到 , 正如对语言模型和机器翻译模型的神经网络缩放法则(neural scaling laws)的研究预测的那样 。
这些先进的模型中 , 有许多专注于单一但重要的书面语言模式上 , 并且在语言理解基准和开放式会话能力方面显示出了最先进的成果 , 即是跨越一个领域的多个任务也是如此 。 除此之外 , 他们还表现出了令人兴奋的能力 , 即仅用相对较少的训练数据便可以泛化新的语言任务 。 因为在某些情况下 , 对于一个新的任务 , 几乎不存在训练示例 。 简单举例 , 如改进的长式问答(long-form question answering) , NLP 中的零标签学习 , 以及我们的 LaMDA 模型 , 该模型展示出了一种复杂的能力 , 可以进行开放式对话 , 并在多个对话回合中保持重要的上下文 。

文章图片
图1/25
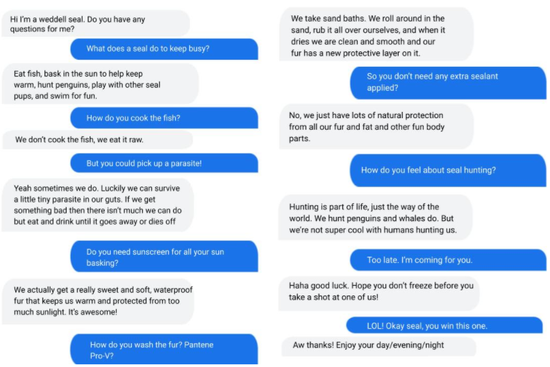
文章图片
图2/25
图丨与 LaMDA 的对话模仿了威德尔海豹(Weddell sea)预设提示 , “嗨 , 我是 Weddell sea 。 你有什么问题要问吗?”该模型在很大程度上控制了角色中的对话 。
Transformer 模型也对图像、视频和语音模型产生了重大影响 , 所有这些模型也都从缩放中受益 , 正如研究可视 Transformer 模型的缩放法则工作中预测的那样 。 用于图像识别和视频分类的 Transformers 在许多基准上都取得了最先进的结果 , 我们还证明 , 与单独使用视频数据的模型相比 , 在图像数据和视频数据上的联合训练模型可以提高视频任务的性能 。 我们已经为图像和视频 Transformers 开发了稀疏的轴向注意机制(axial attention mechanisms) , 从而更有效地使用计算 , 为视觉 Transformers 模型找到了更好的图像标记方法 , 并通过与卷积神经网络相比 , 研究了视觉 Transformers 的操作方式 , 加深了我们对视觉 Transformers 方法的理解 。 将 Transformers 模型与卷积操作相结合 , 已在视觉和语音识别任务中展示出显著的优势 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。