所有这些趋势都指向训练能够处理多种数据模式并解决数千或数百万任务的高能力通用模型的方向 。 通过构建稀疏性模型 , 使得模型中唯一被给定任务激活的部分是那些针对其优化过的部分 , 由此一来 , 这些多模态模型可以变得更加高效 。 在未来的几年里 , 我们将在名为“Pathways”的下一代架构和综合努力中追求这一愿景 。 随着我们把迄今为止的许多想法结合在一起 , 我们期望在这一领域看到实质性的进展 。
文章图片
图6/25
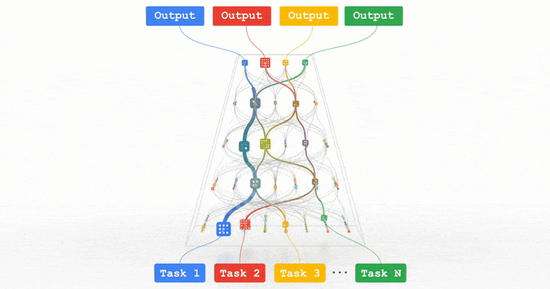
图丨Parthway:我们正在朝着单一模型的描述而努力 , 它可以在数百万个任务中进行泛化 。
趋势2:ML 的持续效率提高
由于计算机硬件设计、ML 算法和元学习(meta-learning)研究的进步 , 效率的提高正在推动 ML 模型向更强的能力发展 。 ML 管道的许多方面 , 从训练和执行模型的硬件到 ML 体系结构的各个组件 , 都可以在保持或提高整体性能的同时进行效率优化 。 这些不同的线程中的每一个都可以通过显着的乘法因子来提高效率 , 并且与几年前相比 , 可以将计算成本降低几个数量级 。 这种更高的效率使许多关键的进展得以实现 , 这些进展将继续显著地提高 ML 的效率 , 使更大、更高质量的 ML 模型能够以更有效的成本开发 , 并进一步普及访问 。 我对这些研究方向感到非常兴奋!
ML加速器性能的持续改进:
每一代ML加速器都在前几代的基础上进行了改进 , 使每个芯片的性能更快 , 并且通常会增加整个系统的规模 。 其中 , 拥有大量芯片的 pods , 这些芯片通过高速网络连接在一起 , 可以提高大型模型的效率 。
当然 , 移动设备上的 ML 能力也在显著增加 。 Pixel 6 手机配备了全新的谷歌张量处理器(Google Tensor processor) , 集成了强大的ML加速器 , 以更好地支持重要的设备上功能 。
我们使用 ML 来加速各种计算机芯片的设计(下面将详细介绍) , 这也带来了好处 , 特别是在生产更好的 ML 加速器方面 。

文章图片
图7/25
持续改进的 ML 编译和 ML 工作负载的优化:
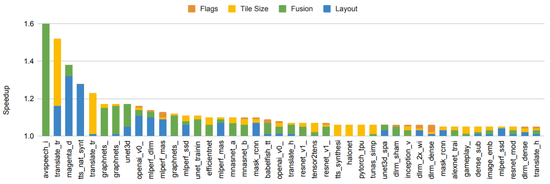
即使在硬件没有变化的情况下 , 对于 ML 加速器的编译器和系统软件的其他优化也可以显著提高效率 。 例如 , “自动调优多通道机器学习编译器的灵活方法”展示了如何使用 ML 来执行编译设置的自动调优 , 从而在相同的底层硬件上为一套 ML 程序实现 5-15%(有时高达 2.4 倍的改进)的全面性能改进 。 GSPMD 描述了一个基于 XLA 编译器的自动并行化系统 , 该系统能够扩展大多数深度学习网络架构 , 超出加速器的内存容量 , 并已应用于许多大型模型 , 如 GShard-M4、LaMDA、BigSSL、ViT、MetNet-2 和 GLaM 等等 , 在多个领域上带来了最先进的结果 。
文章图片
图8/25
图丨在 150 ML 模型上使用基于 ML 的编译器自动调优 , 可以加快端到端模型的速度 。 包括实现 5% 或更多改进比例的模型 。 条形颜色代表了优化不同模型组件的相对改进程度 。
人类创造力驱动的更高效模型架构的发现:
模型体系结构的不断改进 , 大大减少了许多问题达到给定精度水平所需的计算量 。 例如 , 我们在 2017 年开发的 Transformer 结构 , 能够在几个 NLP 任务和翻译基准上提高技术水平 。 与此同时 , 可以使用比各种其他流行方法少 10 倍甚至百倍的计算来实现这些结果 , 例如作为 LSTMs 和其他循环架构 。 类似地 , 视觉 Transformer 能够在许多不同的图像分类任务中显示出改进的最新结果 , 尽管使用的计算量比卷积神经网络少 4 到 10 倍 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。