更高效模型架构的机器驱动发现:
神经体系结构搜索(NAS, Neural Architecture Search)可以自动发现对于给定的问题域更有效、新颖的 ML 体系结构 。 NAS 的主要优势是 , 它可以大大减少算法开发所需的工作量 , 因为 NAS 在每个搜索空间和问题域组合中只需要一次性的工作 。 此外 , 虽然最初执行 NAS 的工作可能在计算上很昂贵 , 但由此产生的模型可以大大减少下游研究和生产环境中的计算 , 从而大大减少整体资源需求 。 例如 , 为了发现演化 Transformer(Evolved Transformer)而进行的一次性搜索只产生了 3.2 吨的 CO2e , 但是生成了一个供 NLP 社区中的任何人使用的模型 , 该模型比普通的 Transformer 模型的效率高 15-20% 。 最近对 NAS 的使用发现了一种更高效的体系结构 Primer(开源) , 与普通的 Transformer 模型相比 , 它降低了4倍的训练成本 。 通过这种方式 , NAS 搜索的发现成本通常可以通过使用发现的更高效的模型体系结构得到补偿 , 即使它们只应用于少数下游任务 。
文章图片
图9/25
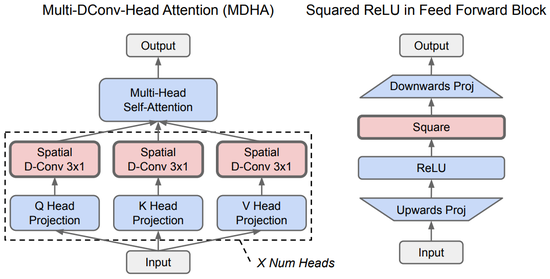
图丨与普通的 Transformer 模型相比 , NAS 发现的 Primer 架构的效率是前者的4倍 。 这幅图(红色部分)显示了 Primer 的两个主要改进:深度卷积增加了注意力的多头投影和 squared ReLU 的激活(蓝色部分表示原始 Transformer) 。
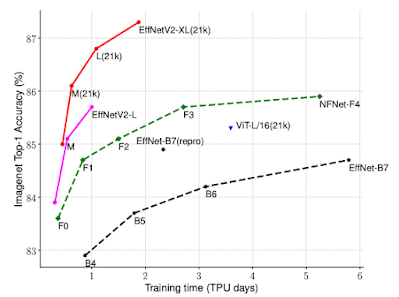
NAS 还被用于发现视觉领域中更有效的模型 。 EfficientNetV2 模型体系结构是神经体系结构搜索的结果 , 该搜索联合优化了模型精度、模型大小和训练速度 。 在 ImageNet 基准测试中 , EfficientNetV2 提高了 5 到 11 倍的训练速度 , 同时大大减少了先前最先进模型的尺寸 。 CoAtNet 模型架构是通过一个架构搜索创建的 , 该架构搜索采用了视觉 Transformer 和卷积网络的想法 , 以创建一个混合模型架构 , 其训练速度比视觉 Transformer 快 4 倍 , 并取得了新的 ImageNet 技术水平 。
文章图片
图10/25
图丨与之前的 ImageNet 分类模型相比 , EfficientNetV2 获得了更好的训练效率 。
搜索的广泛应用有助于改进 ML 模型体系结构和算法 , 包括强化学习(RL , Reinforcement Learning)和进化技术(evolutionary techniques)的使用 , 激励了其他研究人员将这种方法应用到不同的领域 。 为了帮助其他人创建他们自己的模型搜索 , 我们有一个开源的模型搜索平台 , 可以帮助他们探索发现其感兴趣的领域的模型搜索 。 除了模型架构之外 , 自动搜索还可以用于发现新的、更有效的强化学习算法 , 这是在早期 AutoML-Zero 工作的基础上进行的 , 该工作演示了自动化监督学习算法发现的方法 。
稀疏的使用:
稀疏性是算法的另一个重要的进步 , 它可以极大地提高效率 。 稀疏性是指模型具有非常大的容量 , 但对于给定的任务、示例或 token , 仅激活模型的某些部分 。 2017 年 , 我们推出了稀疏门控专家混合层(Sparsely-Gated Mixture-of-Experts Layer) , 在各种翻译基准上展示了更好的性能 , 同时在计算量上也保持着一定的优势 , 比先前最先进的密集 LSTM 模型少 10 倍 。 最近 , Switch Transformer 将专家混合风格的架构与 Transformer 模型架构结合在一起 , 在训练时间和效率方面比密集的 T5-Base Transformer 模型提高了 7 倍 。 GLaM 模型表明 , Transformer 和混合专家风格的层可以组合在一起 , 可以产生一个新的模型 。 该模型在 29 个基准线上平均超过 GPT-3 模型的精度 , 使用的训练能量减少 3 倍 , 推理计算减少 2 倍 。 稀疏性的概念也可以用于降低核心 Transformer 架构中注意力机制的成本 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。