视频是由一系列图像帧(Frame)组成的 , 图像分类模型经过这些年的发展已经相对成熟 。 如何进行视频分类呢?一种直观的想法是将图像分类的模型直接运用到视频分类中 。 如下图所示 , 一个简单的想法是先把视频各帧提取出来 , 每帧图像各自前馈(Feedforward)一个图像分类模型 , 不同帧的图像分类模型之间相互共享参数 。 得到每帧图像的特征之后 , 对各帧图像特征进行汇合(Pooling) , 例如采用平均汇合 , 得到固定维度的视频特征 , 最后经过一个全连接层和 Softmax 激活函数进行分类以得到视频的类别预测 。
【视频理解综述:动作识别、时序动作定位、视频Embedding】

文章图片
图 3:利用图像分类模型和平均汇合进行动作识别网络结构图 。 本图源于《深度学习视频理解》
平均汇合方法十分简单 , 其视频分类的准确率与其他同时期专门为动作识别设计的深度学习模型相比差距并不大 (Karpathy et al., 2014), 但是与传统动作识别算法的准确率相比还有很大差距 , 不过后来专门为动作识别设计的深度学习模型的准确率高了很多 。
最直观的想法是先把视频拆成一帧帧的图像 , 每帧图像各自用一个图像分类模型得到帧级别的特征 , 然后用某种汇合方法从帧级别特征得到视频级别特征 , 最后进行分类预测 , 其中的汇合方法包括: 平均汇合、NetVLAD/NeXtVLAD、NetFV、RNN、3D 卷积等 。 另外 , 我们可以借助一些传统算法来补充时序关系 , 例如 , 双流法利用光流显式地计算帧之间的运动关系 , TDD 利用 iDT 计算的轨迹进行汇合等 。 基于 2D 卷积的动作识别方法的一个优点是可以快速吸收图像分类领域的最新成果 , 通过改变骨架网络 , 新的图像分类模型可以十分方便地迁移到基于 2D 卷积的动作识别方法中 。
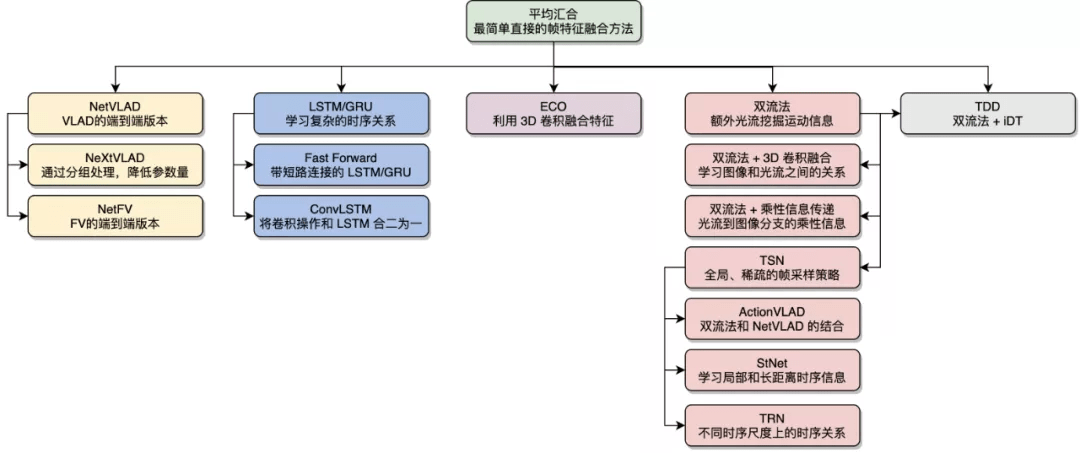
文章图片
图 4:基于 2D 卷积的动作识别算法 。 本图源于《深度学习视频理解》
2.3 基于 3D 卷积的动作识别
另一方面 , 图像是三维的 , 而视频比图像多了一维 , 是四维 。 图像使用的是 2D 卷积 , 因此视频使用的是 3D 卷积 。 我们可以设计对应的 3D 卷积神经网络 , 就像在图像分类中利用 2D 卷积可以从图像中学习到复杂的图像表示一样 , 利用 3D 卷积可以从视频片段中同时学习图像特征和相邻帧之间复杂的时序特征 , 最后利用学到的高层级特征进行分类 。
相比于 2D 卷积 , 3D 卷积可以学习到视频帧之间的时序关系 。 我们可以将 2D 卷积神经网络扩展为对应的 3D 卷积神经网络 , 如 C3D、Res3D/3D ResNet、LTC、I3D 等 。 由于 3D 卷积神经网络的参数量和计算量比 2D 卷积神经网络大了很多 , 不少研究工作专注于对 3D 卷积进行低秩近似 , 如 FSTCN、P3D、R(2+1)D、S3D 等 。 TSM 对 2D 卷积进行改造以近似 3D 卷积的效果 。 3D 卷积 + RNN、ARTNet、Non-Local、SlowFast 等从不同角度学习视频帧之间的时序关系 。 此外 , 多网格训练和 X3D 等对 3D 卷积神经网络的超参数进行调整 , 使网络更加精简和高效 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。