如图 10 所示 , 输入一个未被剪辑的视频 , 首先利用动作识别网络提取视频特征 , 之后利用多层 CDC 层同时对特征进行空间维度的下采样和时间维度的上采样 , 进而得到视频中每帧的预测结果 , 最后结合候选时序区间得到动作类别和起止时刻的预测 。 CDC 的一个优点是预测十分高效 , 在单 GPU 服务器下 , 可以达到 500 FPS(Frames per Second , 帧每秒)的预测速度 。
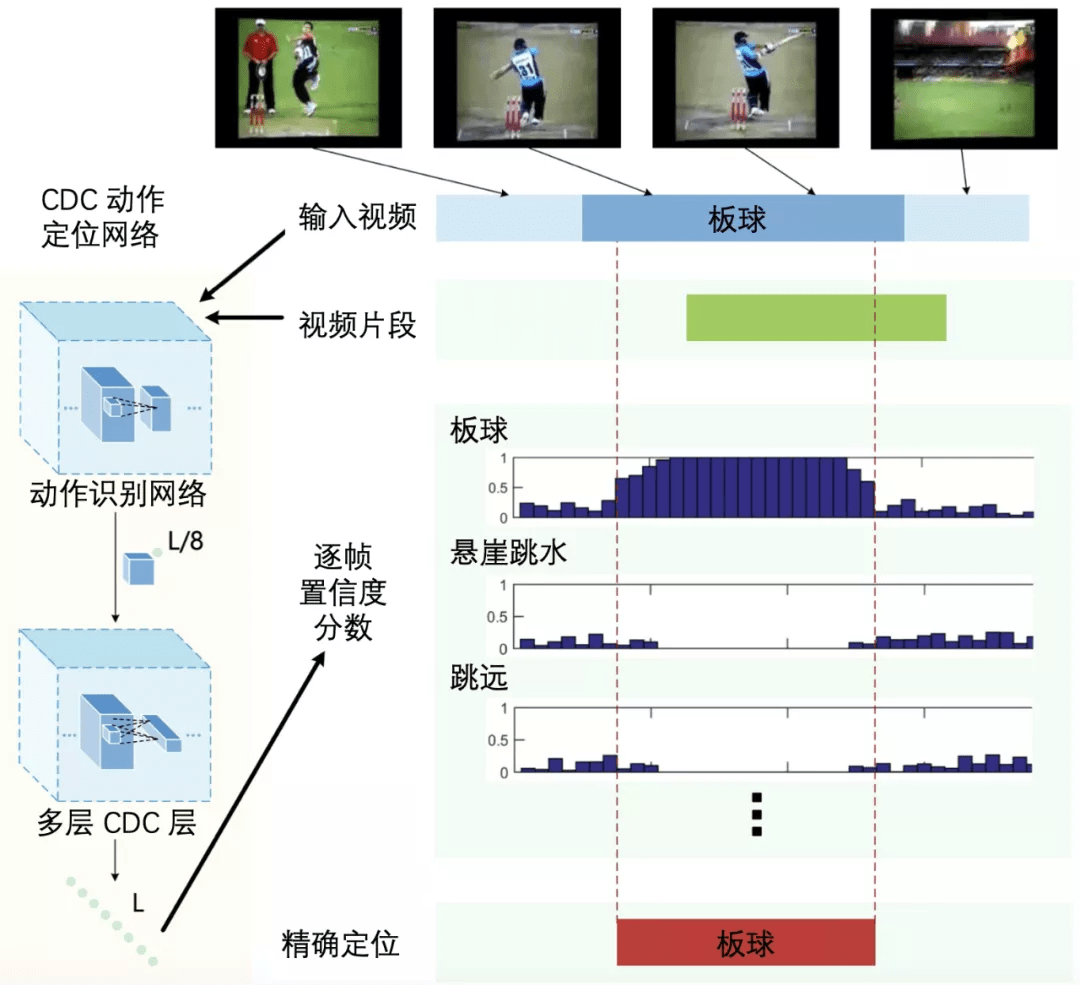
文章图片
图 10:CDC 网络结构图 。 本图源于《深度学习视频理解》
3.6 单阶段算
目标检测算法可以大致分为两大类 , 其中一大类算法为两阶段算法 , 两阶段算法会先从图像中预测可能存在目标的候选区域 , 之后逐一判断每个候选区域的类别 , 并对候选区域边界进行修正 。 时序动作定位中也有一些算法采用了两阶段算法的策略 , 先从视频中预测可能包含动作的候选时序区间 , 之后逐一判断每个候选时序区间的类别 , 并对候选时序区间的边界进行修正 , 这部分算法已在 3.2 节介绍过 。
另一大类算法为单阶段 (One-Stage) 算法 , 单阶段算法没有单独的候选区域生成的步骤 , 直接从图像中预测 。 在目标检测领域中 , 通常两阶段算法识别精度高 , 但是预测速度慢 , 单阶段算法识别精度略低 , 但是预测速度快 。 时序动作定位中也有一些算法采用了单阶段算法的策略 。
到此为止 , 我们了解了许多时序动作定位算法 , 一种直观的想法是预先定义一组不同时长的滑动窗 , 之后滑动窗在视频上进行滑动 , 并逐一判断每个滑动窗对应的时序区间内的动作类别 , 如 S-CNN 。 TURN 和 CBR 以视频单元作为最小计算单位避免了滑动窗带来的冗余计算 , 并且可以对时序区间的边界进行修正; 受两阶段目标检测算法的启发 , 基于候选时序区间的算法先从视频中产生一些可能包含动作的候选时序区间 , 之后逐一判断每个候选时序区间内的动作类别 , 并对区间边界进行修正 , 如 R-C3D 和 TAL-Net; 自底向上的时序动作定位算法先预测动作开始和结束的时刻 , 之后将开始和结束时刻组合为候选时序区间 , 如 BSN、TSA-Net 和 BMN;SSN 不仅会预测每个区间的动作类别 , 还会 预测区间的完整性; CDC 通过卷积和反卷积操作可以逐帧预测动作类别 。 此外 , 单阶段目标检测的思路也可以用于时序动作定位中 , 如 SSAD、SS-TAD 和 GTAN 。

文章图片
图 11:时序动作定位算法 。 本图源于《深度学习视频理解》
4. 视频 Embedding
Embedding 直译为嵌入 , 这里译为向量化更贴切 。 视频 Embedding 的目标是从视频中得到一个低维、稠密、浮点的特征向量表示 , 这个特征向量是对整个视频内容的总结和概括 。 其中 , 低维是指视频 Embedding 特征向量的维度比较低 , 典型值如 128 维、256 维、512 维、1024 维等; 稠密和稀疏 (Sparse) 相对 , 稀疏是指特征向量中有很多元素为 0 , 稠密是指特征向量中很多元素为非 0; 浮点是指特征向量中的元素都是浮点数 。
不同视频 Embedding 之间的距离 (如欧式距离或余弦距离) 反映了对应视频之间的相似性 。 如果两个视频的语义内容接近 , 则它们的 Embedding 特征之间的距离近 , 相似度高; 反之 , 如果两个视频不是同一类视频 , 那么它们的 Embedding 特征之间的距离远 , 相似度低 。 在得到视频 Embedding 之后 , 可以用于视频推荐系统、视频检索、视频侵权检测等多个任务中 。
动作识别和时序动作定位都是预测型任务 , 即给定一个视频 , 预测该视频中出现的动作 , 或者更进一步识别出视频中出现的动作的起止时序区间 。 而视频 Embedding 是一种表示型任务 , 输入一个视频 , 模型给出该视频的向量化表示 。 视频 Embedding 算法可以大致分为以下 3 大类 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。