机器之心发布
作者:张皓
本文将介绍视频理解中的三大基础领域:动作识别(Action Recognition)、时序动作定位(Temporal Action Localization)和视频 Embedding 。1.视频理解背景
根据中国互联网络信息中心(CNNIC)第 47 次《中国互联网络发展状况统计报告》 , 截至 2020 年 12 月 , 中国网民规模达到 9.89 亿人 , 其中网络视频(含短视频)用户规模达到 9.27 亿人 , 占网民整体的 93.7% , 短视频用户规模为 8.73 亿人 , 占网民整体的 88.3% 。
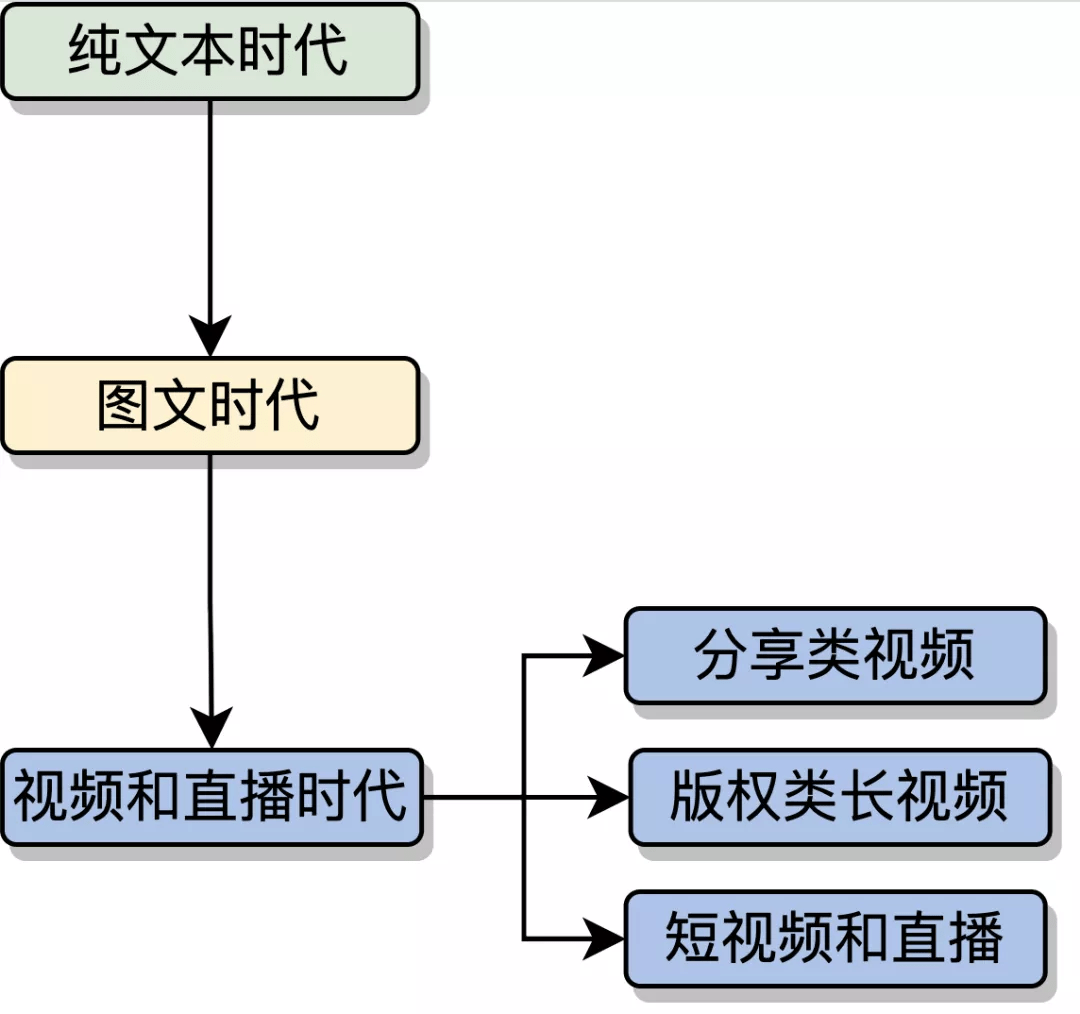
回顾互联网近年来的发展历程 , 伴随着互联网技术(特别是移动互联网技术)的发展 , 内容的主流表现形式经历了从纯文本时代逐渐发展到图文时代 , 再到现在的视频和直播时代的过渡 , 相比于纯文本和图文内容形式 , 视频内容更加丰富 , 对用户更有吸引力 。
文章图片
图 1:互联网内容表现形式的 3 个阶段 。 本图源于《深度学习视频理解》
随着近年来人们拍摄视频的需求更多、传输视频的速度更快、存储视频的空间更大 , 多种场景下积累了大量的视频数据 , 需要一种有效地对视频进行管理、分析和处理的工具 。 视频理解旨在通过智能分析技术 , 自动化地对视频中的内容进行识别和解析 。 视频理解算法顺应了这个时代的需求 。 因此 , 近年来受到了广泛关注 , 取得了快速发展 。
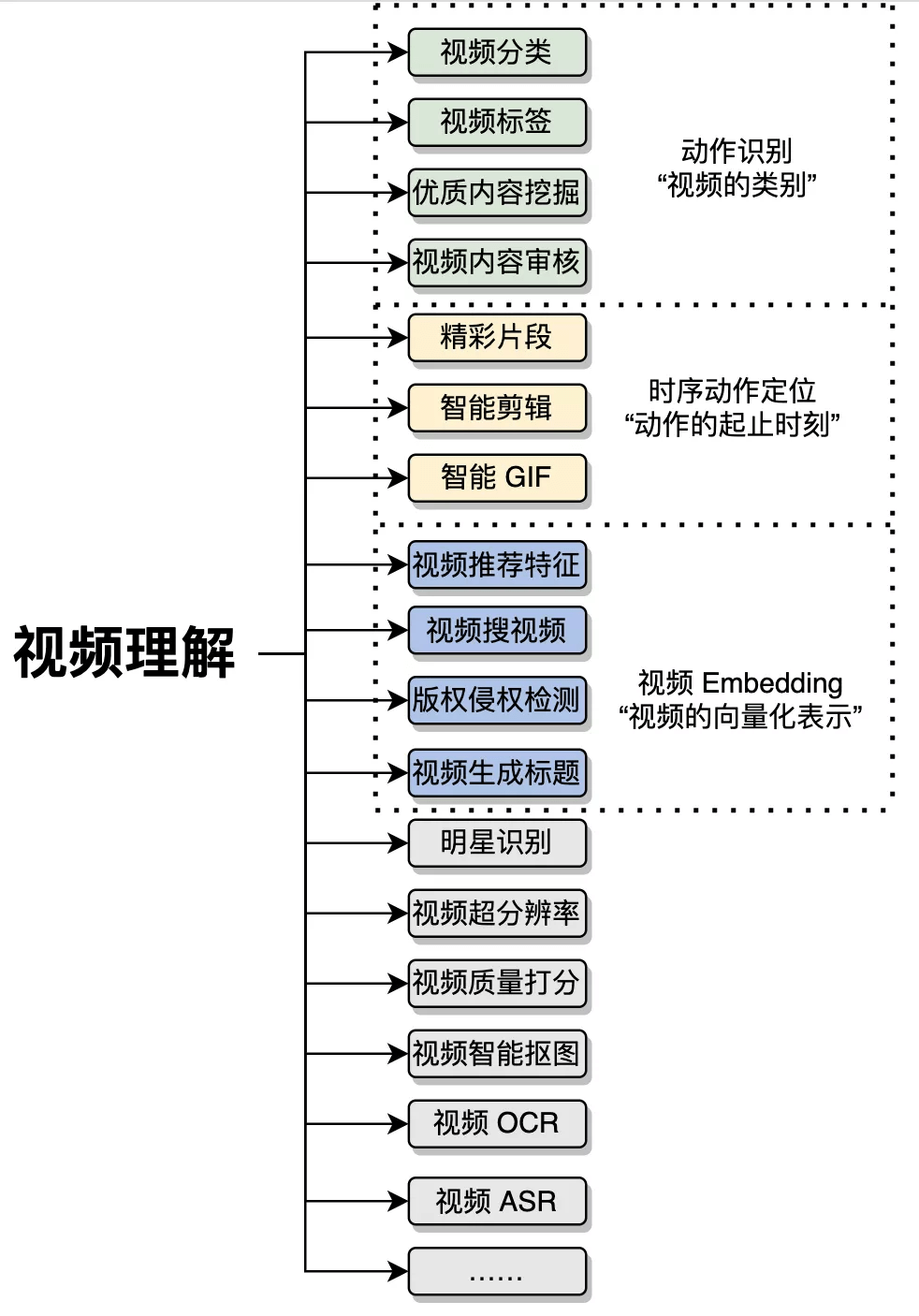
视频理解涉及生活的多个方面 , 目前视频理解已经发展成一个十分广阔的学术研究和产业应用方向 。 受篇幅所限 , 本文将介绍视频理解中的三大基础领域: 动作识别 (Action Recognition)、时序动作定位(Temporal Action Localization) 和视频 Embedding 。
文章图片
图 2:视频理解涉及的部分任务 。 本图源于《深度学习视频理解》
2. 动作识别(Action Recognition)
2.1 动作识别简介
动作识别的目标是识别出视频中出现的动作 , 通常是视频中人的动作 。 视频可以看作是由一组图像帧按时间顺序排列而成的数据结构 , 比图像多了一个时间维度 。 动作识别不仅要分析视频中每帧图像的内容 , 还需要从视频帧之间的时序信息中挖掘线索 。 动作识别是视频理解的核心领域 , 虽然动作识别主要是识别视频中人的动作 , 但是该领域发展出来的算法大多数不特定针对人 , 也可以用于其他视频分类场景 。
动作识别看上去似乎是图像分类领域向视频领域的一个自然延伸 , 深度学习尽管在图像分类领域取得了举世瞩目的成功 , 目前深度学习算法在图像分类上的准确率已经超过普通人的水平 , 但是 , 深度学习在动作识别领域的进展并不像在图像分类领域那么显著 , 很长一段时间基于深度学习算法的动作识别准确率达不到或只能接近传统动作识别算法的准确率 。 概括地讲 , 动作识别面临以下几点困难:
- 训练视频模型所需的计算量比图像大了一个量级 , 这使得视频模型的训练时长和训练所需的硬件资源相比图像大了很多 , 导致难以快速用实验进行验证和迭代;
- 在 2017 年 , Kinetics 数据集 (Carreira & Zisserman, 2017) 诞生之前 ,缺少大规模通用的视频基准 (Benchmark) 数据集 。 在很长一段时间里 , 研究者都是在如 UCF-101 数据集 (Soomro et al., 2012) 上比较算法准 确率 , 而 UCF-101 只有 1.3 万条数据 , 共 101 个类别 , 平均每个类别只有约 100 个视频 , 相比于图像分类领域的 ImageNet 数据集有 128 万 条数据 , 共 1000 个类别 , 平均每个类别约有 1,000 个视频 , UCF-101 数据集显得十分小 。 数据集规模制约了动作识别领域的发展;
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。