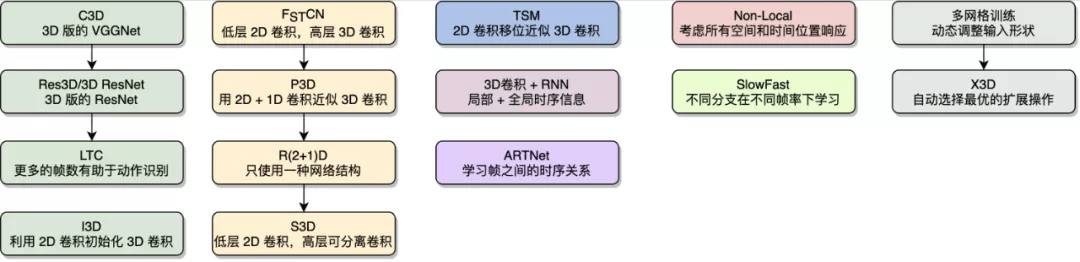
文章图片
图 5:基于 3D 卷积的动作识别算法 。 本图源于《深度学习视频理解》
3. 时序动作定位(Temporal Action Localization)
时序动作定位 (Temporal Action Localization) 也称为时序动作检测 (Temporal Action Detection) , 是视频理解的另一个重要领域 。 动作识别可以看作是一个纯分类问题 , 其中要识别的视频基本上已经过剪辑(Trimmed) , 即每个视频包含一段明确的动作 , 视频时长较短 , 且有唯一确定的动作类别 。 而在时序动作定位领域 , 视频通常没有被剪辑(Untrimmed) , 视频时长较长 , 动作通常只发生在视频中的一小段时间内 , 视频可能包含多个动作 , 也可能不包含动作 , 即为背景(Background) 类 。 时序动作定位不仅要预测视频中包含了什么动作 , 还要预测动作的起始和终止时刻 。 相比于动作识别 , 时序动作定位更接近现实场景 。
时序动作定位可以看作由两个子任务组成 , 一个子任务是预测动作的起止时序区间 , 另一个子任务是预测动作的类别 。 由于动作识别领域经过近年来的发展 , 预测动作类别的算法逐渐成熟 , 因此时序动作定位的关键是预测动作的起止时序区间 , 有不少研究工作专注于该子任务 , ActivityNet 竞赛除了每年举办时序动作定位竞赛 , 还专门组织候选时序区间生成竞赛(也称为时序动作区间提名) 。
既然要预测动作的起止区间 , 一种最朴素的想法是穷举所有可能的区间 , 然后逐一判断该区间内是否包含动作 。 对于一个 T 帧的视频 , 所有可能的区间为, 穷举所有的区间会带来非常庞大的计算量 。
时序动作检测的很多思路源于图像目标检测 (Object Detection) , 了解目标检测的一些常见算法和关键思路对学习时序动作定位很有帮助 。 相比于图像分类的目标是预测图像中物体的类别 , 目标检测不仅要预测类别 , 还要预测出物体在图像中的空间位置信息 , 以物体外接矩形的包围盒(Bounding Box) 形式表示 。
3.1 基于滑动窗的算法
这类算法的基本思路是预先定义一系列不同时长的滑动窗 , 之后滑动窗在视频上沿着时间维度进行滑动 , 并逐一判断每个滑动窗对应的时序区间内具体是什么动作类别 。 图 6 (a) 中使用了 3 帧时长的滑动窗 , 图 6 (b) 中使用了 5 帧时长的滑动窗 , 最终汇总不同时长的滑动窗的类别预测结果 。 可以知道 , 该视频中包含的动作是悬崖跳水、动作出现的起止时序区间在靠近视频结尾的位置 。
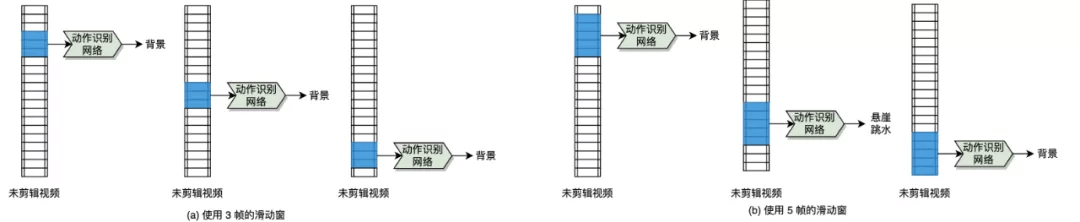
文章图片
图 6:基于滑动窗的算法流程图 。 本图源于《深度学习视频理解》
如果对目标检测熟悉的读者可以联想到 , Viola-Jones 实时人脸检测器 (Viola & Jones, 2004) 中也采用了滑动窗的思想 , 其先用滑动窗在图像上进行密集滑动 , 之后提取每个滑动窗对应的图像区域的特征 , 最后通过 AdaBoost 级联分类器进行分类 。 Viola-Jones 实时人脸检测器是计算机视觉历史上具有里程碑意义的算法之一 , 获得了 2011 年 CVPR(Computer Vision and Pattern Recognition , 计算机视觉和模式识别)大会用于表彰十年影响力的 Longuet-Higgins 奖 。
3.2 基于候选时序区间的算法
目标检测算法中的两阶段 (Two-Stage) 算法将目标检测分为两个阶段: 第一阶段产生图像中可能存在目标 的候选区域(Region Proposal) , 一般一张图像可以产生成百上千个候选区域 , 这一阶段和具体的类别无关; 第二阶段逐一判断每个候选区域的类别并对候选区域的边界进行修正 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。