类比于两阶段的目标检测算法 , 基于候选时序区间的时序动作定位算法也将整个过程分为两个阶段: 第一阶段产生视频中动作可能发生的候选时序区间; 第 二阶段逐一判断每个候选时序区间的类别并对候选时序区间的边界进行修正 。 最终将两个阶段的预测结果结合起来 , 得到未被剪辑视频中动作的类别和起止时刻预测 。
文章图片
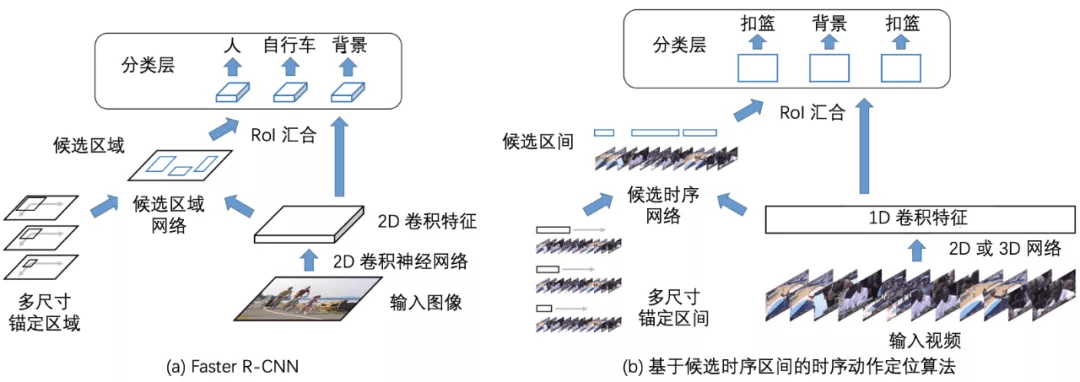
图 7:Faster R-CNN 和基于候选时序区间的方法类比 。 本图源于《深度学习视频理解》
3.3 自底向上的时序动作定位算法
基于滑动窗和基于候选时序区间的时序动作定位算法都可以看作是自顶向下的算法 , 其本质是预先定义好一系列不同时长的滑动窗或锚点时序区间 , 之后判断每个滑动窗位置或锚点时序区间是否包含动作并对边界进行微调以产生候选时序区间 。 这类自顶向下的算法产生的候选时序区间会受到预先定义的滑动窗或锚点时序区间的影响 , 导致产生的候选时序区间不够灵活 , 区间的起止位置不够精确 。
本节介绍自底向上的时序动作定位算法 , 这类算法首先局部预测视频动作开始和动作结束的时刻 , 之后将开始和结束时刻组合成候选时序区间 , 最后对每个候选时序区间进行类别预测 。 相比于自顶向下的算法 , 自底向上的算法预测的候选时序区间边界更加灵活 。 了解人体姿态估计 (Human Pose Estimation) 的读者可以联想到 , 人体姿态估计也可以分为自顶向下和自底向上两类算法 , 其中自顶 向下的算法先检测出人的包围盒 , 之后对每个包围盒内检测人体骨骼关键点 , 如 (Chen et al., 2018) 等; 自底向上的算法先检测所有的人体骨骼关键点 , 之后再组合成人 , 如 (Cao et al., 2021) 等 。
BSN(Boundary Sensitive Network , 边界敏感网络)(Lin et al., 2018b)是自底向上的时序动作定位算法的一个实例 , BSN 获得了 2018 年 ActivityNet 时序动作定位竞赛的冠军和百度综艺节目精彩片段预测竞赛的冠军 。
文章图片
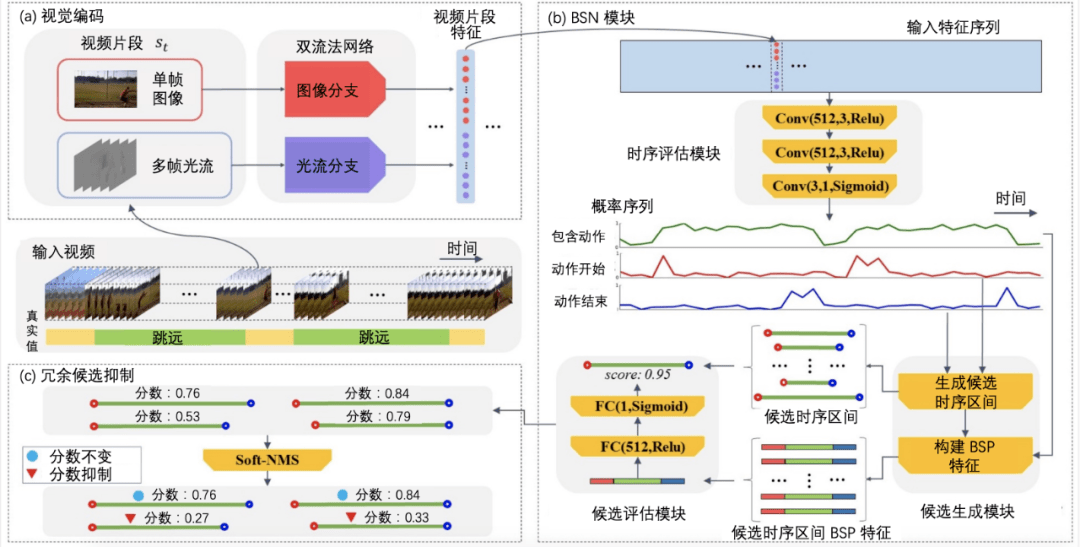
图 8:BSN 网络结构图 。 本图源于《深度学习视频理解》
3.4 对时序结构信息建模的算法
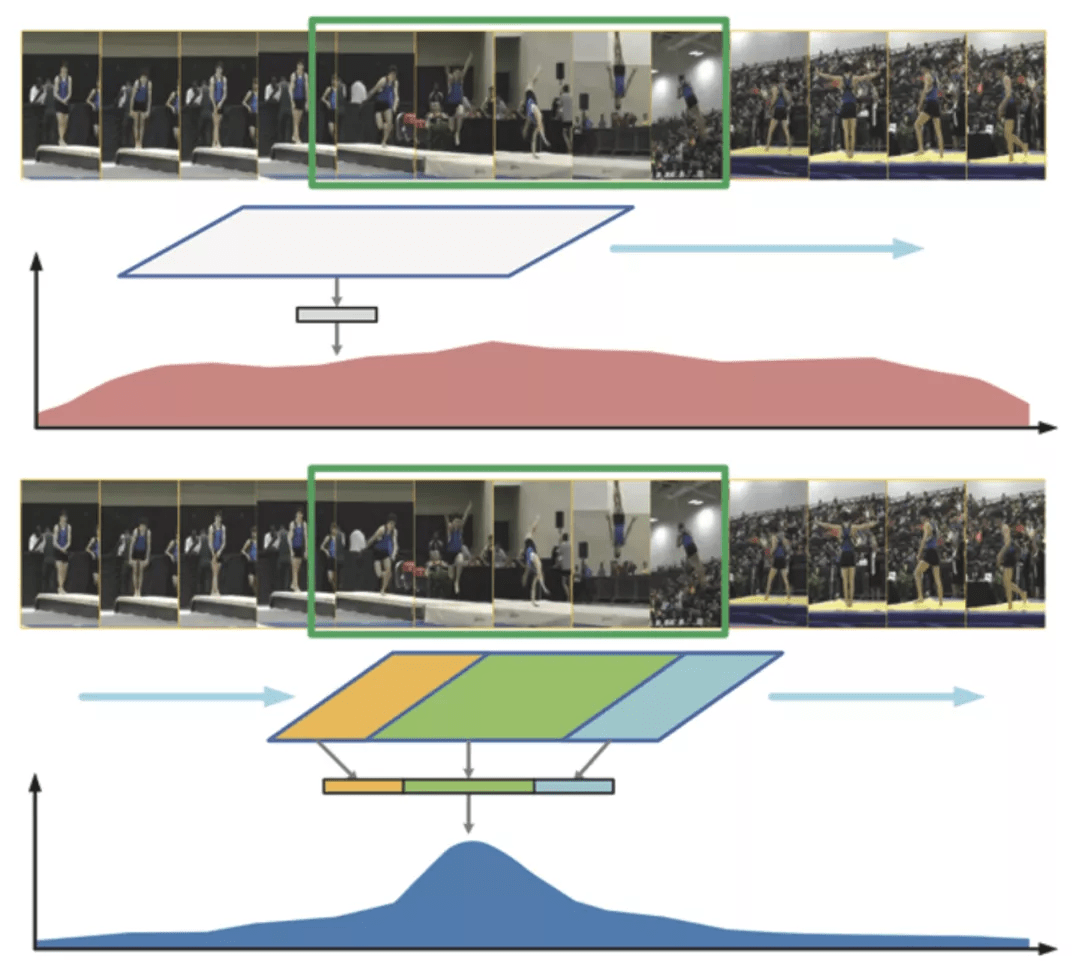
假设我们的目标是识别视频中的体操单跳 (Tumbling) 动作和对应的动作起止区间 , 见图 9 中的绿色框 。 图 9 中的蓝色框表示模型预测的候选时序区间 , 有的候选时序区间时序上并不完整 , 即候选时序区间并没有覆盖动作完整的起止过程 。 图 9 上半部分的算法直接基于候选时序区间内的特征对候选时序区间内的动作类别进行预测 , 导致模型一旦发现任何和单跳动作有关的视频片段 , 就会输出很高的置信度 , 进而导致时序定位不够精准 。
文章图片
图 9:SSN 对动作不同的阶段进行建模 。 本图源于(Zhao et al., 2020)
SSN(Structured Segment Network , 结构化视频段网络)算法 (Zhao et al., 2020) 对动作不同的阶段 (开始、过程、结束) 进行建模 , SSN 不仅会预测候选时序区间内的动作类别 , 还会预测候选时序区间的完整性 , 这样做的好处是可以更好地定位动作开始和结束的时刻 , SSN 只在候选时序区间和动作真实起止区间对齐的时候输出高置信度 。
3.5 逐帧预测的算法
我们希望模型对动作时序区间的预测能够尽量精细 。 CDC (Convolutional-De-Convolutional networks , 卷积 - 反卷积网络)算法 (Shou et al., 2017) 和前文介绍的其他算法的不同之处在于 , CDC 可以对未被剪辑的视频逐帧预测动作的类别 , 这种预测粒度十分精细 , 使得对动作时序区间边界的定位更加精确 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。