第一类方法基于视频内容有监督地学习视频 Embedding 。 我们基于视频的类别有监督地训练一个动作识别网络 , 之后可以从网络的中间层 (通常是全连接层) 提取视频 Embedding 。 这类方法的重点在于动作识别网络的设计 。
第二类方法基于视频内容无监督地学习视频 Embedding 。 第一类方法需要大量的视频标注 , 标注过程十分耗时、耗力 , 这类方法不需要额外的标注 , 从视频自身的结构信息中学习 , 例如 , 视频重建和未来帧预测、视频帧先后顺序验证、利用视频 和音频信息、利用视频和文本信息等 。
第三类方法通过用户行为学习视频 Embedding 。 如果我们知道每个用户的视频观看序列 , 由于用户有特定类型的视频观看喜好 , 用户在短时间内一起观看的视频通常有很高的相似性 , 利用用户观看序列信息 , 我们可以学习得到视频 Embedding 。
其中 , 第一类和第二类方法基于视频内容学习视频 Embedding , 它们的优点是没有视频冷启动问题 , 即一旦有新视频产生 , 就可以计算该视频的 Embedding 用于后续的任务中 。 例如 , 这可以对视频推荐系统中新发布的视频给予展示机会; 基于内容的视频 Embedding 的另一个优点是对所有的视频“一视同仁” , 不会推荐过于热门的视频 。 另外 , 也可以为具有小众兴趣爱好的用户进行推荐 。
一旦新视频获得了展示机会 , 积累了一定量的用户反馈 (即用户观看的行为数据) 之后 , 我们就可以用第三类方法基于用户行为数据学习视频 Embedding ,有时视频之间的关系比较复杂 , 有些视频虽然不属于同一个类别 , 但是它们之间存在很高的相似度 , 用户常常喜欢一起观看 。 基于用户行为数据学习的视频 Embedding 可以学习到这种不同类别视频之间的潜在联系 。
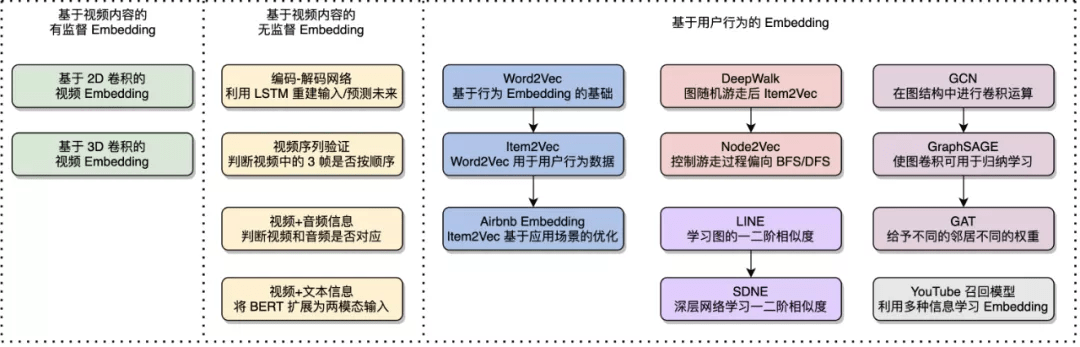
第三大类方法通过用户行为学习视频 Embedding , 其中 Item2Vec 将自然语言处理中经典的 Word2Vec 算法用到了用户行为数据中 , 并在后续工作中得到了优化 , DeepWalk 和 Node2Vec 基于图的随机游走学习视频 Embedding , 是介于图算法和 Item2Vec 算法之间的过渡 , LINE 和 SDNE 可以学习图中结点的一阶和二阶相似度 , GCN GraphSAGE 和 GAT 等将卷积操作引入到了图中 , YouTube 召回模型利用多种信息学习视频 Embedding 。
文章图片
图 12:视频 Embedding 算法 。 本图源于《深度学习视频理解》
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。